
在当今复杂的 Web 应用世界中,API 优化性能至关重要。无论是前端用户体验,还是后端服务响应,任何一个环节的瓶颈都可能导致用户流失和业务损失。
Server-Timing 和 Open Telemetry (OTel) 是两个流行的 API 全链路观测工具,但其侧重点、应用场景和哲学理念却截然不同。本文主要对比两个工具的差别,了解哪个工具更适合你的项目。
Server-Timing
Server-Timing 是一个 HTTP 响应头(Response Header),是 W3C 标准一部分:,允许服务器在响应中向浏览器报告关于请求处理过程中的性能指标。
原理
它主要用于揭示后端处理请求的耗时细节,并将这些信息直接传递给前端,主要包含 3 个属性:
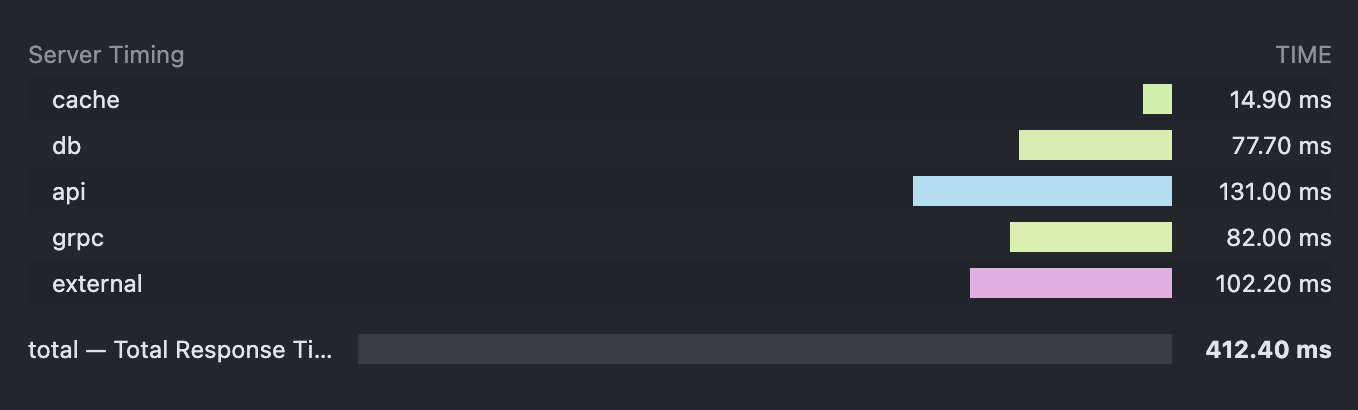
- name:观测项目的名称,比如 db、cache、api。
- duration:服务执行耗时,通常以毫秒为单位,缩写为 dur。
- description:观测项目的描述,缩写为 desc。
比如要表示后端的数据库调用耗时为 50ms,可以返回一个 Header:
Server-Timing: db;dur=50;desc="Get user info from db"
属性之间用 ; 符合隔开,如果有多个观测指标,使用 , 逗号进行分隔。
下面是浏览器面板上看到的效果:
优缺点
优点:
- 开箱即用,集成简单(对于前端):一旦服务器配置好,前端无需任何额外的 JavaScript 代码或库,无需额外监控系统,就能在浏览器开发工具中直接看到数据。这是它最大的优势之一。
- 轻量级,性能开销低:仅仅是添加一个 HTTP 头,对请求的性能影响微乎其微。
- 直观展示后端耗时(浏览器友好):与浏览器原生的网络瀑布流完美结合,开发者可以非常清晰地看到每一个请求中,服务器端各个阶段的耗时。
- 跨语言/平台通用:只要能设置 HTTP 响应头的后端服务,无论是 Node.js、Python、Java 还是 Go,都可以使用。
缺点:
- 仅限于单个请求的后端时间:它只能报告当前 HTTP 请求的后端处理时间。无法追踪分布式系统中的跨服务调用、异步任务、批处理作业等。
- 数据格式和语义受限:虽然你可以定义描述,但它本质上是扁平的键值对,缺乏层级结构和丰富的上下文信息。
Open Telemetry
OpenTelemetry(简称 OTel)是一个由 Cloud Native Computing Foundation (CNCF) 孵化的开源可观测性框架,旨在提供一套统一的 API、SDK 和工具,用于收集和导出遥测数据(Metrics、Logs、Traces)。它是一个厂商中立(vendor-neutral)的标准,目标是解决可观测性领域的碎片化问题。
原理
想象一个请求(比如你点击一个网页):
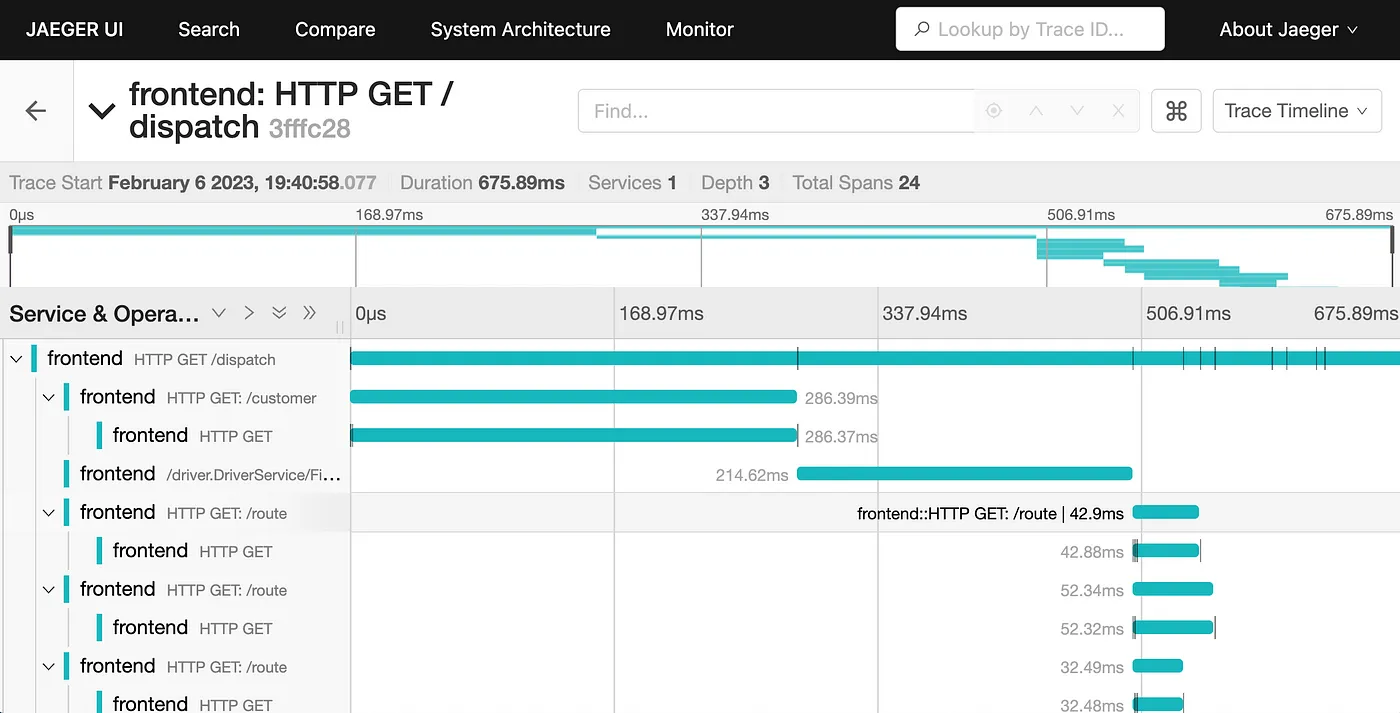
- 整个旅程 = Trace (追踪):从你点击到网页显示,所有后台发生的事情加起来,就是一个“Trace”,它有一个总的 ID(Trace ID),就像一个故事的主线。
- 旅程中的每一步 = Span (跨度):这个大旅程里有许多小步骤,比如:
- 你的浏览器发起请求(一个 Span)。
- 网关接收请求(一个 Span)。
- 网关调用订单服务(一个 Span)。
- 订单服务查询数据库(又一个 Span)。
每个 Span 都有自己的 ID 和 持续时间,还能带上额外信息(比如查询的SQL)。
当一个服务调用另一个服务时,OTel 会把当前 Trace 的 Trace ID 和上一步的 Span ID 悄悄地加到 HTTP 请求头里,下一个服务收到请求时,就读取 Header,知道自己属于哪个 Trace,并且上一跳是哪个 Span。这样,所有的 Span 就通过父子关系(谁调用了谁)和共同的 Trace ID 串联起来,形成一个完整的调用链。
应用程序通过 OTel 库自动或手动“记录”(专业术语叫“埋点”)这些 Span 信息。记录完后,这些 Span 会被发送出去(“导出”)到一个专门的后端系统(比如 Jaeger)。这些后端系统会把这些 Span 可视化,画出清晰的调用链路图,让你一眼就能看出哪个环节慢了,甚至哪里出错了。
优缺点
优点:
- 统一日志的上下文信息,与 Trace 相关联。
- 分布式追踪(Distributed Tracing):这是其核心优势,能够清晰地展示一个请求在微服务架构中如何流转,哪个服务是瓶颈,哪个调用失败。
- 丰富的上下文信息:每个 Span 可以携带大量的属性(attributes),如用户ID、订单ID、服务版本、请求参数等,极大地方便了故障排查和性能分析。
- 可编程性强,高度定制化:开发者可以在代码中自由地创建 Span、添加属性、记录事件,实现细粒度的性能监控。
- 厂商中立与生态系统:OTel 生成的数据可以导出到任何支持 OTel 协议的后端(如 Jaeger, Zipkin, Prometheus, Grafana Loki, 以及各种商业 APM 产品如 Datadog, New Relic, Dynatrace 等),避免了厂商锁定。
- 复杂分析与自动化:数据可被聚合、分析、用于构建仪表盘、设置告警,甚至驱动自动化运维。
缺点:
- 学习曲线:理解 Traces, Spans, Context Propagation, Exporters 等概念需要时间。
- 侵入性(相对):需要在代码中进行大量的植入(手动或自动),尤其是在大型、复杂的遗留系统中。
- 部署和维护:需要部署 Collector、选择或部署后端存储和分析工具(如 Jaeger、Grafana Mimir/Loki),维护成本相对较高。
- 性能开销(相对):虽然 OTel 本身优化良好,但大量的 Tracing 数据生成、传输和处理,相较于简单的 HTTP 头,会有更高的资源消耗。尤其是在高并发场景下,需要仔细配置采样策略。
对比总结:Server-Timing vs. OpenTelemetry
| 特性 | Server-Timing | OpenTelemetry |
|---|---|---|
| 核心目的 | 快速告知前端后端单个请求的处理耗时。 | 提供全栈、端到端的遥测数据(Logs, Metrics, Traces)实现分布式系统可观测性。 |
| 数据类型 | 扁平的键值对计时信息(HTTP Header)。 | 结构化的 Span、Trace、Metrics、Logs。 |
| 作用范围 | 单个 HTTP 请求的后端处理。 | 跨服务、跨进程、跨语言的完整请求链路。 |
| 集成难度 | 非常简单(前端无需代码),后端修改 HTTP 头。 | 复杂,需在代码中植入、理解概念,部署和维护后端系统。 |
| 性能开销 | 极低。 | 相对高,数据量大,需考虑采样和传输开销。 |
| 可视化 | apiping.io、浏览器开发者工具(Network Tab)。 | 专业的 APM 工具(Jaeger, Grafana, Datadog 等)。 |
| 上下文信息 | 有限,仅描述计时。 | 丰富,可附加任意业务属性和事件。 |
| 分析能力 | 无,仅单次展示。 | 强大,可聚合、趋势分析、告警、定位瓶颈。 |
| 适用场景 | 快速调试,简单后端性能概览。 | 微服务、分布式系统、复杂业务、全链路故障排查、长期性能监控。 |
| 厂商依赖 | 无。 | 中立,可导出到任何支持 OTel 协议的后端。 |
总结
对大部分项目来说,应该优先选择 Server-Timing 作为性能观测手段,这几乎是一个免费的性能优化和排查工具,而且无需引入复杂的监控体系。你总能在最接近用户的视角看到网站、App 的访问性能体验,理解整个 API 链路中最值得优化的环节。